Amazon EBS Adds Support for Tagging EBS Snapshots Upon Creation and Resource-Level Permissions
See the announcement here
Amazon EBS Adds Support for Tagging EBS Snapshots Upon Creation and Resource-Level Permissions
See the announcement here
In a previous post I experimented with serverless monitoring of my websites. I was wondering if I could extend the monitoring functions to gather rudimentary data on the time it takes to load the site.
I decided to modify the Lambda function I used earlier to calculate the time it took for the function to read the response back from the server. This is most certainly not the best way to monitor page load times or any form of synthetic browser monitoring, but it gives me a bird’s-eye view of the trends and can alert me if for any reason this changes unexpectedly.
The python code I create is here:
Disclaimer: I am sure this can be optimised quite a bit, but it does illustrate the general idea).
import boto3
import urllib2
import socket
from time import time
import os
def write_metric(value, metric):
d = boto3.client('cloudwatch')
d.put_metric_data(Namespace='Web Status',
MetricData=[
{
'MetricName':metric,
'Dimensions':[
{
'Name': 'Status',
'Value': 'Page Load Time',
},
],
'Value': value,
},
]
)
def check_site(url):
load_time = 0.005
try:
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((url, 443))
except socket.error, e:
print("[Error:] Cannot connect to site %s" %url)
return 0.005
else:
print("Checking %s Page Load time" % url)
start_time = time()
request = urllib2.Request("http://" + url)
response = urllib2.urlopen(request)
output = response.read()
end_time = time()
response.close()
load_time = round(end_time-start_time, 3)
return load_time
def lambda_handler(event, context):
websiteurl = str(os.environ.get('websiteurl'))
metricname = websiteurl + ' Page Load'
r = check_site(websiteurl)
print(websiteurl + " loaded in %r seconds" %r)
write_metric(r, metricname)
I run a couple of websites for personal use, Nextcloud (an open source Dropbox alternative) and this WordPress site for personal use using a single EC2 instance. As this architecture is susceptible to a host of problems due to a lack of redundancy, I needed a way to keep an eye on site availability and get notified if the websites were unavailable for any reason.
I had a couple of basic requirements:
There were a few ways I could solve this:
I only need to check if the websites are up every 5 minutes, so any solution requiring the use of a virtual server or container that runs all the time would be a waste of resources, not to mention expensive. As a result, I chose to use a serverless function that is triggered every 5 minutes using AWS Lambda which gives me solution that is “almost free”, i.e. a few cents a month.
The basic architecture for this serverless monitoring is as follows:
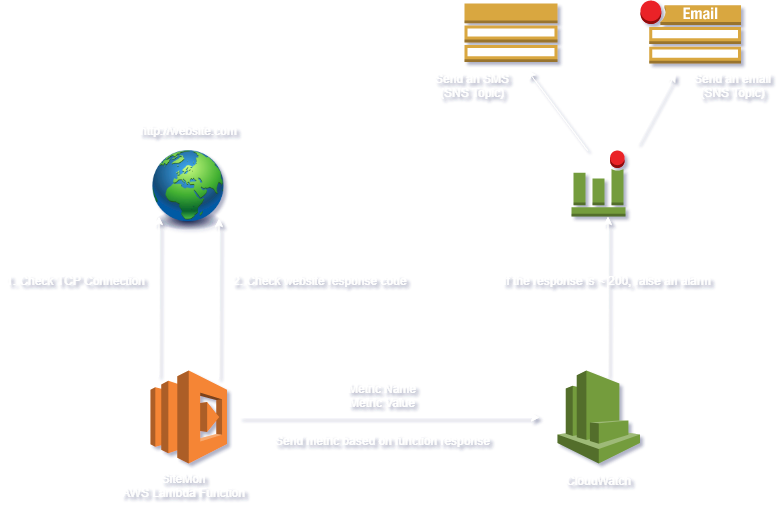
Here’s a checklist of things that need to be in place for this to work:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AllowLogCreation",
"Effect": "Allow",
"Action": [
"logs:CreateLogStream",
"logs:PutLogEvents",
"logs:CreateLogGroup"
],
"Resource": "arn:aws:logs:*:*:*"
},
{
"Sid": "AllowMetricAlarmCreation",
"Effect": "Allow",
"Action": [
"cloudwatch:PutMetricAlarm",
"cloudwatch:PutMetricData"
],
"Resource": "*"
},
]
}
If you have a database on an EC2 instance, the question that comes up frequently is “how do I backup my database and where?”. The easiest option is to backup to Amazon’s S3 storage. This post shows you how to achive an automated database backup to S3 using a simple shell scripts that can be run on the database server.
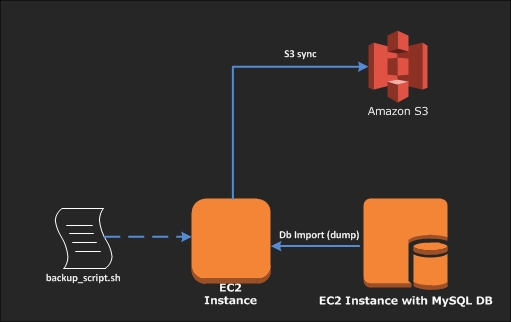
Here’s a checklist of things that need to be in place for this to work:
Install awscli dependencies (if they do not already exist)
Run pip –version to see if your version of Linux already includes Python and pip
$ pip --version
If you don’t have pip, install pip as follows:
$ curl -O https://bootstrap.pypa.io/get-pip.py $ sudo python get-pip.py
Verify pip is successfuly installed:
$ pip --version pip 9.0.3 from /usr/local/lib/python2.7/dist-packages (python 2.7)
For detailed installation and troubleshooting go here: https://pip.pypa.io/en/stable/installing/
Installing the AWS CLI with Pip
Now use pip to install the AWS CLI:
$ pip install awscli --upgrade
Verify that the AWS CLI installed correctly.
$ aws --version aws-cli/1.14.63 Python/2.7.12 Linux/4.4.0-1049-aws botocore/1.9.16
Configuring AWS CLI
The aws configure command is the fastest way to set up your AWS CLI installation.
$ aws configure AWS Access Key ID [None]: AKIAIOSFODNN7EXAMPLE AWS Secret Access Key [None]: wJalrXUtnFEMI/K7MDENG/bPxRfiCYEXAMPLEKEY Default region name [None]: us-east-1 Default output format [None]: json
For detailed AWS CLI configuration and installation options go here: https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-getting-started.html
Now that we have all the dependencies set up, lets go ahead and create the bash script to back up our database: